
Nei casi più fortunati, semplici modelli statistico-matematici aiutano a capire i fenomeni empirici e a prevederne il futuro. Nei casi un po’ meno fortunati, ci si riesce ancora, ma occorrono modelli più complicati. Nei casi più frequenti, però, e purtroppo, anche i modelli complicati non fanno bene il loro mestiere: danno indicazioni, sì, ma con un margine di errore elevato.
Incertezze e stranezze
Lo stesso è avvenuto con la pandemia da Covid-19. In parte ciò si deve all’incertezza sui dati: ad esempio, data la natura del virus, spesso asintomatico o paucisintomatico, non si è ancora veramente saputo quanti sono stati i contagiati e in che momento è avvenuto il loro contagio. Si conoscono i positivi alla prova del tampone, ma si reputa che questi siano solo una frazione (10%?) degli infettati: ne sapremo di più probabilmente solo dopo l’indagine campionaria che l’Istat ha lanciato a partire dal 25 maggio, in collaborazione con Ministero della Salute e Croce Rossa. Persino i decessi, che pure continuano ad apparire come il termine meno incerto di tutto il quadro, non sono univocamente attribuibili al Coronavirus: in alcuni casi, soprattutto all’inizio, alcuni possono essere sfuggiti alla rilevazione, mentre in seguito i decessi “con” Coronavirus non sono necessariamente stati causati “dal” Coronavirus.
A oggi, ci sono poi forti e in parte misteriose differenze territoriali, in termini, ad esempio di:
- tamponi (dai 164 per mille della provincia di Trento ai 29 per mille della Puglia),
- casi (9 per mille in Val d’Aosta ma solo 0,6 per mille in Calabria),
- mortalità (1,6 per mille in Lombardia ma 0,05 per mille in Basilicata),
- letalità apparente del virus (rapporto tra decessi e positivi: 18% in Lombardia, 5% in Molise; Tab. 1).
Una curva modello. Anzi facciamo due
Come si diceva, molti, e talvolta anche complessi, sono i modelli proposti per descrivere e proiettare al futuro gli eventi sanitari prodotti dal Coronavirus. Neodemos però, come suo costume, ha privilegiato un approccio relativamente semplice, concentrandosi sui casi (i positivi al tampone) e sui decessi con Covid, e ne ha descritto l’andamento con una curva che deriva dalla “normale”, o “gaussiana”, ma che se ne discosta perché introduce un grado di libertà in più.
La normale è una curva simmetrica, che si pensa adatta a descrivere bene molti fenomeni, tra cui anche l’evoluzione di una pandemia, sia nel caso di assenza di intervento umano (curva viola, alta, a sinistra nella fig. 1), sia nel caso di presenza di tale intervento, ad esempio con misure di confinamento (curva azzurrina, bassa, a destra nella Fig. 1).

In concreto, però, quel che tipicamente succede è che l’intervento umano si attivi proprio a causa della presenza del virus. In termini modellistici questo significa che nessuna delle due curve della Fig. 1 si adatta bene al caso in esame. Ma forse è possibile pensare a una sintesi delle due, con una parte iniziale in cui gli eventi giornalieri aumentano seguendo la curva viola (senza intervento umano) e una parte successiva in cui gli eventi decrescono seguendo invece un modello da curva azzurrina (con intervento umano).
Questo “ibrido” tra due diverse curve normali funziona meglio della versione “pura”, come si vede, ad esempio, dalla fig. 2, che segue i decessi giornalieri con Coronavirus dal 15 febbraio al 3 maggio; la bontà di adattamento ai dati della curva modificata è decisamente superiore (l’Rquadro aggiustato, ad esempio, passa da circa 87% a circa 96%).
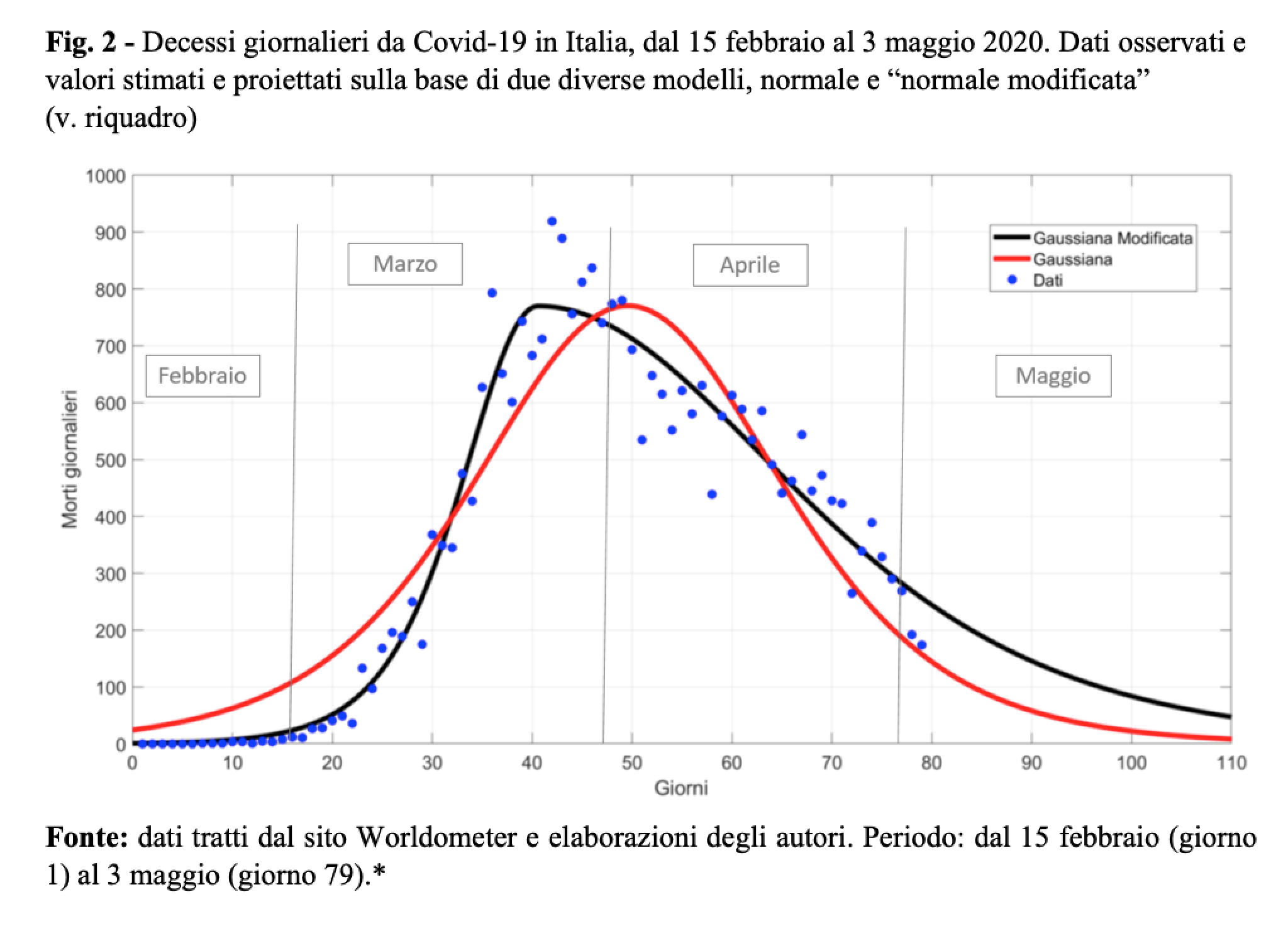
Riveste un certo interesse anche seguire l’andamento cumulativo dei casi, e cioè l’evoluzione del totale dall’inizio fino al momento dell’osservazione, indicato in ascissa. Se la base per gli eventi giornalieri è una curva normale, il totale è ben descritto da una curva logistica; se invece la base è una normale modificata, anche la cumulata risulterà in una “logistica modificata” (fig. 3; in questo caso, Rquadro aggiustato passa da 0.9961 a 0.9999).

Paragrafo per modellisti (astenersi gli altri)
In realtà si è stimata prima la curva logistica modificata della fig. 3, con la formula
![]()
dove y è il totale dei casi osservati fino a quel momento, e è la costante di Nepero (2.71828…), t il tempo, contato in giorni (15/2/2020=1) e gli altri quattro sono parametri da stimare empiricamente. Lasciamo un attimo da parte a, cui diamo inizialmente il valore neutro di 1 (che, tra l’altro, annulla la parentesi quadra a destra). Il parametro k, in una logistica “tradizionale”, rappresenta il numero massimo di casi che saranno osservati alla fine del processo, g un parametro che regola la velocità di crescita della curva, e m è il giorno “di svolta”, cioè il momento in cui si raggiunge il massimo dei nuovi eventi giornalieri (in seguito il fenomeno rallenterà). Fin qui, la curva logistica “classica”.
Ora entra in ballo il parametro aggiuntivo a, che, per costruzione, vale 1 fino a che t<m (cioè nel ramo sinistro della curva, fino al giorno m), ma che da quel momento in poi assume un valore da determinare, e che empiricamente si rivela essere positivo ma minore di 1 (tra 0,25 e 0,30), il che contribuisce a “indebolire” g, e cioè la velocità di crescita. La presenza del nuovo parametro a, però pone due problemi aggiuntivi. Il primo è che nel punto t=m si vuole che i due rami della curva (sinistro e destro) coincidano, e questo si ottiene solo aggiungendo una costante, che è data dalla parentesi quadra della formula (1). Il secondo è che il massimo (per t→∞, cioè dopo moltissimi giorni) diventa non k (come nella logistica tradizionale), ma k(a+1)/2a. La derivata della funzione (1) è la “gaussiana” (o “normale”) della fig. 2 e dell’equazione 2
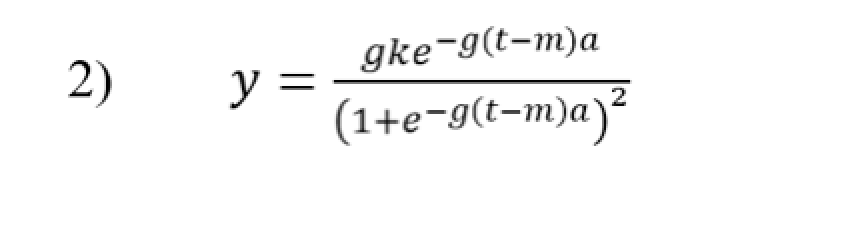
dove variabili e parametri sono gli stessi visti prima, con lo stesso significato, e con la stessa peculiarità di “a”, pari a 1 fino al punto di massimo, e successivamente libero di assumere un valore qualunque.
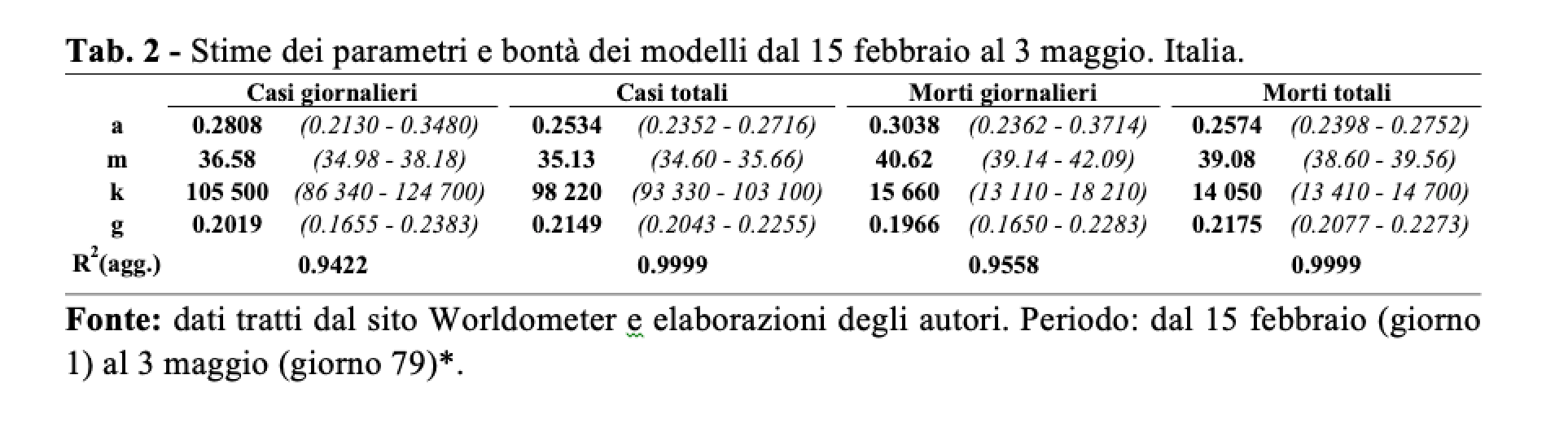
Empiricamente, stimare i parametri (nel periodo 1-79, e cioè dal 15 febbraio al 3 maggio) nei due casi non porta esattamente agli stessi risultati, anche se, ovviamente, le differenze sono molto ridotte, sia nel caso dei decessi sia in quello dei casi (Tab. 2).
Pre e post 3 maggio
In Italia, come in altri paesi, il quadro è però più complicato di quel che i modelli lasciano intuire. Intanto per le già accennate differenze territoriali, per cui forse non si può parlare di una sola Italia (neanche in questo caso!) e poi perché le misure di distanziamento fisico (non “sociale”) sono state prima più blande (a partire dal 21 febbraio), poi più severe (dal 9 marzo), e infine di nuovo più permissive (gradualmente, a partire dal 4 maggio).
Dal punto di vista del modello questo richiederebbe l’introduzione di diversi parametri aggiuntivi di tipo a. Ma non lo abbiamo fatto. Abbiamo invece deciso di ignorare le misure (blande) del 21 febbraio, considerare implicitamente solo quelle (severe) dal 9 marzo e stimare i parametri per il periodo dal 15 febbraio al 3 maggio (giorni 1-79). I risultati delle stime così ottenute li abbiamo usati per proiettare gli eventi “futuri”, e cioè dal 4 al 31 maggio (giorni 80-107).
Oltre a tenere il modello entro limiti di complicazione accettabili, questa scelta ha il vantaggio di permettere un confronto: se il modello è “buono” (e questo è un grosso “se”), la differenza tra i valori osservati e quelli proiettati potrebbe dare un’indicazione degli effetti dell’allentamento delle restrizioni. In altre parole, potremmo ricavare qualche indicazione sull’eventuale temuta recrudescenza del fenomeno a seguito dai minori vincoli sul distanziamento fisico.
I risultati sono mostrati nella Fig. 4 e, per gli ultimi giorni, dal 4 maggio in poi, nella Tab. 3.
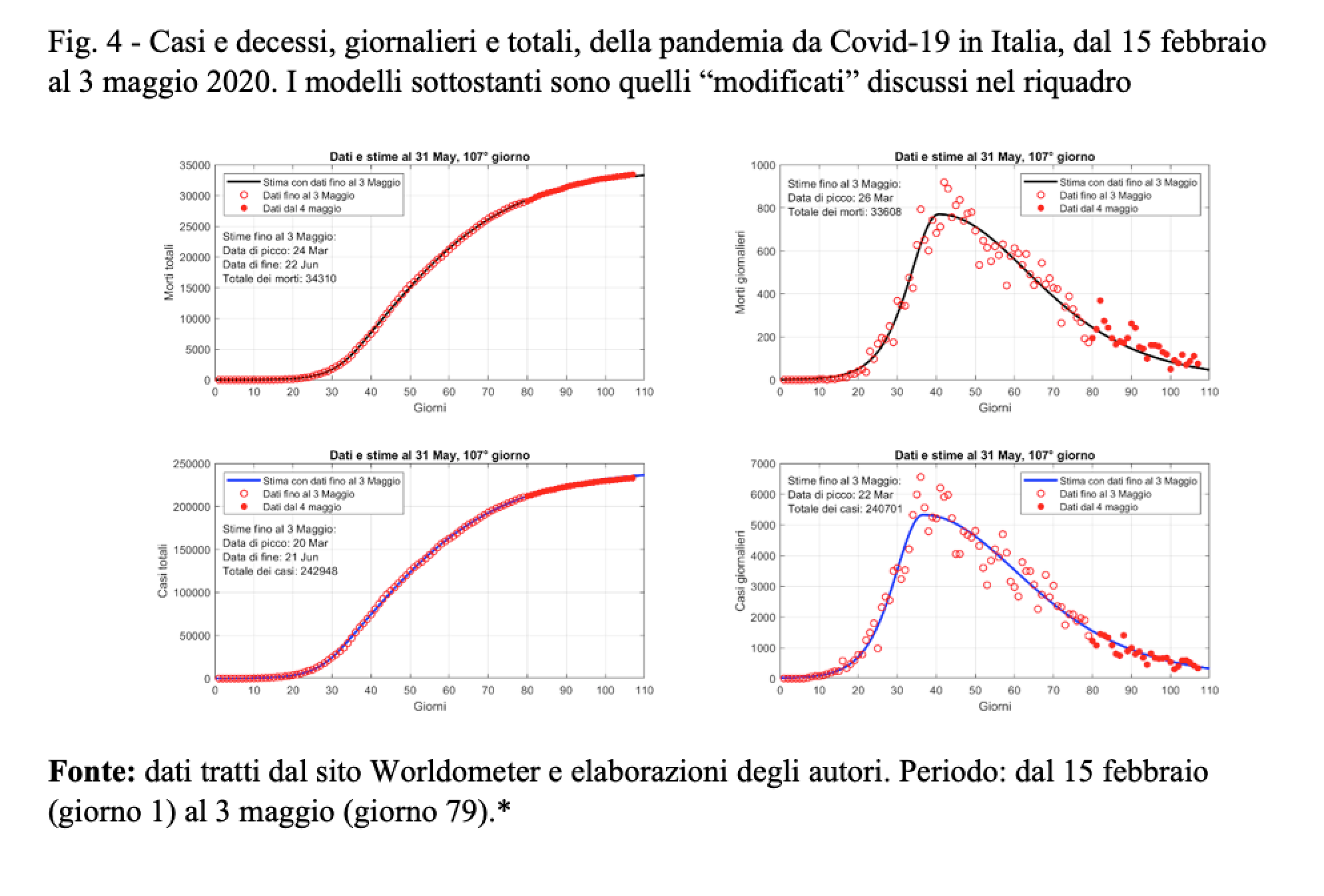
 Nonostante l’ottimo adattamento ai dati osservati fino al 3 maggio (Tab. 2 e Fig. 4), il modello non è perfetto quando si tratta di proiettare i risultati al futuro, dal 4 al 31 maggio, e questo sia per i “casi”, cioè per le persone risultate positive al tampone, sia per i decessi. Per ragioni non chiare, il modello sottostima i decessi e sovrastima i casi, quando, semmai, sarebbe stato lecito attendersi un valore più elevato proprio per questi ultimi, visto l’aumento del numero dei tamponi e l’allentamento delle misure di prevenzione (confinamento). La buona notizia è che non sembrano per ora esserci i segnali della temuta “seconda ondata”, e il prezzo pagato in termini di vittime sarà alla fine verosimilmente modesto, soprattutto in ottica comparativa storica.
Nonostante l’ottimo adattamento ai dati osservati fino al 3 maggio (Tab. 2 e Fig. 4), il modello non è perfetto quando si tratta di proiettare i risultati al futuro, dal 4 al 31 maggio, e questo sia per i “casi”, cioè per le persone risultate positive al tampone, sia per i decessi. Per ragioni non chiare, il modello sottostima i decessi e sovrastima i casi, quando, semmai, sarebbe stato lecito attendersi un valore più elevato proprio per questi ultimi, visto l’aumento del numero dei tamponi e l’allentamento delle misure di prevenzione (confinamento). La buona notizia è che non sembrano per ora esserci i segnali della temuta “seconda ondata”, e il prezzo pagato in termini di vittime sarà alla fine verosimilmente modesto, soprattutto in ottica comparativa storica.
Con una nota di cautela, però. Per come è costruito, il nostro modello non può prevedere una recrudescenza del fenomeno. Ma modelli più complicati possono farlo, e lo fanno. Se ne trova traccia, ad esempio, anche nel sito worldometers da cui abbiamo tratto i nostri dati (v. sezione projections). Lo scenario non è drammatico, ma suggerisce che la pandemia potrebbe non scomparire con l’estate.
Fonti figure 2 – 3 e 4 e tabelle 2 e 3
*dati tratti dal sito Worldometer https://www.worldometers.info/coronavirus/country/italy/ e elaborazioni degli autori. Periodo: dal 15 febbraio (giorno 1) al 3 maggio (giorno 79).